The data aspect of a system is described using a data model. Here we discus data modeling in detail. First we discuss creating a data model. Then we develop a secure data model to show the difference between a data model and a secure data model.
Data Modeling
A data model is used to represent the information architecture (i.e., data aspect) of a system.
Information architecture shows the information aspect of a system.
A data model describes the structure of data objects in a system–their identity, their relationships to other objects, their attributes, and their operations. Here, an object is simply something that we are interested in maintaining information about in an application context. Some of the examples of data objects are employee, customer, order, and vendor.
A Quick View of a Data Model
Figure 2 shows, briefly, an example of a data model for the teller case described in figure 1. The case has been simplified to keep this example simple and illustrative. This model shows the information structure needed to support the activities of a simple bank teller. We have used the UML (Unified Modeling Language) notation to create the model. A three-part rectangle represents an object class. The rectangle is used to show the object name, attributes, and the object operations (services). A line between two objects shows the association between the objects. For example, the line between the account object and the transaction object indicates that an instance of the account object can associate with one or more instances of the transaction object. But one instance of the transaction object associates with only one instance of the account object. A line with a triangular head shows generalization-specialization relationship among objects. For example, object withdrawal is a specialization of object transaction.

Figure 1. Bank Teller Case.
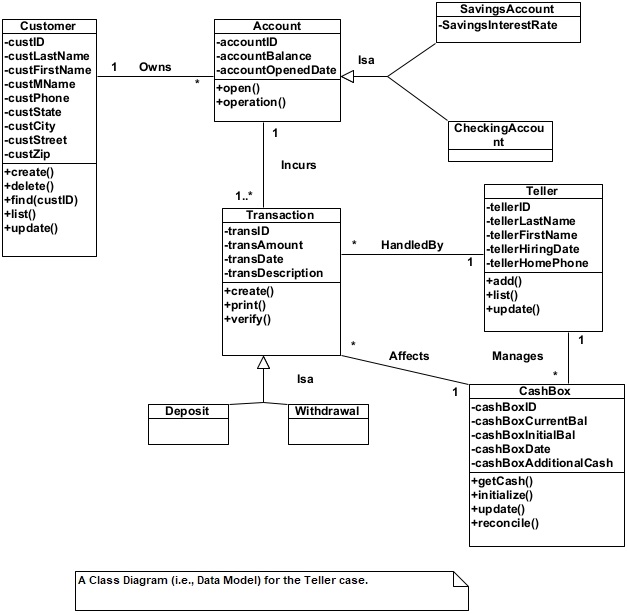
Figure 2. An Object-Oriented Data Model for the Teller case.
As we can see from this example, the structural diagram in figure 1.2 shows various aspects of a data model. It shows:
- Objects,
- Attributes of objects,
- Relationships among objects, and
- Operations (services) on objects.
We will discuss these aspects of the model in detail. We will also show how to develop a data model in a systematic way and how to verify that it is correct and complete with respect to the users’ needs.
Basic Concepts of Data Modeling
Data modeling is an analytical activity. This means that we examine and study a complex, its elements, and their relationships. This leads to the understanding of the complex. This understanding allows us to conceptualize the needed elements and relationships present in the complex. Data modeling is also a conceptual activity. This means that we use various kinds of abstractions to conceive and identify the real
world complex-things into constructs and represent them in some manageable and useable form. Most of the constructs used in data modeling are defined below.
Objects
An object is a construct used to represent things we are interested in maintaining information about. By the term “maintaining information” we mean to store, modify, and keep track of the properties of a thing. This is an important and useful definition of an object. There are many different things in a problem domain. We need to include, in our model, only those things as objects that the user has an interest in maintaining information about. Take the example of the teller case. Things like bank and supervisor are not included in the model as objects. The case treats the bank teller as a system. It limits itself mainly to the tellers’ activities. As per the case, there is no need to maintain any information about the bank or the supervisor. Of course, the scope of this case can be enlarged to add these and other new objects. There are two major factors that affect the scope of a problem and, hence, the identification of objects. These are:
-
- Context of the model and
- Purpose and viewpoint of the model.
The context establishes the subject matter of the model as part of a larger whole. The context helps us create a “boundary” with the environment. This allows us to establish what is external to the model and how it interacts with the model. The boundary is typically specified by defining the interfaces between the model and its environment. This may include interfaces with users as well as other systems.
The purpose relates to the reason(s) a model is created. It refers to the ways a model could be used. For example, a model can be used to study a current problem to define the problem. Another purpose can be to describe how a system is to be designed. The viewpoint refers to the perspective from which a problem is analyzed. Choice of a viewpoint allows a modeler to emphasize certain aspects of a problem and to obscure the other aspects of the problem. For example, when a problem is modeled with the viewpoint of a manager, the managerial aspects of the problem—management and coordination issues are emphasized. A viewpoint can be specified in many ways. For example, a viewpoint can be that of a manager, user, or an analyst.
Attributes
The idea of attributes is used to capture properties of things we are interested in. As an example, let us take the customer as an object. In a given situation, we may want to keep information about the name, address, rating, credit-limit, and phone number of a customer. In that case we can say that name, address, rating, credit-limit, and phone number are the attributes of the customer object. Attributes are used to show the state of an object. They help us capture the appropriate properties of an object to define the object completely and accurately, and uniquely in a given problem situation.
Attributes are user-defined. In other words, the attributes of an object depend upon the needs of the problem at hand.
Relationships
The construct of relationship is used to capture “connection” or correspondence between things. Let us say we have two real world things–customer and order. The customer places, over time, several orders with a company. The company needs to maintain information as to what customers have placed what orders. Making a correspondence between customers and orders can capture this information. We can formalize this correspondence by stating that several orders can be placed by one customer, but an order belongs to only one customer. The above statement about customers and orders basically states an association relationship between a customer and an order. Relationships depend upon business rules. A business rule is a specification of constraints on data. There are several kinds of constraints on data such as identity integrity, referential integrity, domain, and trigger. An identity integrity constraint requires that each object instance be uniquely identifiable. In other words, each object instance has a unique identifier. The referential integrity constraint is concerned with the relationship between objects. It specifies what kind of relationship should exist between objects. The domain constraint pertains to a range of valid values for object-attributes. The trigger (triggering operation) constraint concerns itself with the rules about manipulating object instances and their attribute values. Business rules are precise statements about these constraints. These business rules are formulated with the help of users.
There are several kinds of relationships that can be defined among objects. For
data modeling, the most useful ones are:
- Association,
- Generalization-specialization, and
- Aggregation.
Association
The association relationship represents the “instance connection” among objects. Association relates to mapping between instances of different object types. As an illustration, consider the object types customer and order. Figure 3 shows graphically the instances of customer and order. Lines between the instances show the mapping.
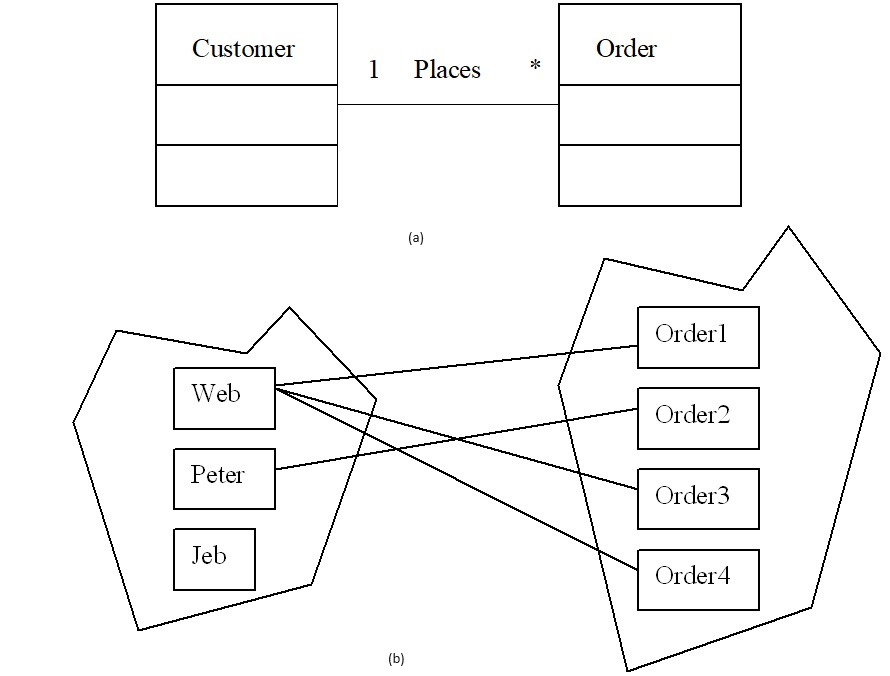
Figur3. (a)–The places relationship and (b)–a graph representing the instances of the relationship Places.
For example, the line between the customer Web and the order order1 represents the mapping from Web to order1 and vice versa. In simple terms, we can say that order1 was placed by Web or Web placed order1. We note that Web has, so far, placed three orders—order1, order3, and order4. There are two instances of the Places relationship in figure 3.
Generalization-specialization
The generalization-specialization relationship is used to capture similarity among things. For example, the statement “an apple is a fruit” indicates that an apple is similar to some fruit. It has the properties of a fruit. Fruit is a more general form of an apple, and an apple is a more specific form of a fruit.
Aggregation
The aggregation relationship is used to show part-subpart correspondence between things.
It is important to note that we capture relationships that show structural connection among objects and not flow through the system.
Operations
The idea of operation is used to specify actions performed on an object. These actions help us create and maintain information about objects. There are two kinds of operations performed on an object–standard and user-defined operations. The standard operations are create, read, update, and delete. These operations apply to all kinds of objects. The user-defined operations are dependent on the problem domain. They are specified based upon the user’s needs.
Development of a Data Model
Development of a data model can be divided into the following steps:
-
- Identification of objects and their attributes
- Identification of relationships among objects and their attributes
- Identification of operations on objects.
- Development of the structure of the model.
Identification of objects in a problem domain depends upon two things:
-
- The nature of the problem and
- The judgment of the user and the analyst.
There is no one correct model of reality. But some models are better than others. We must ask the following questions about a model:
-
- Does the model
- Capture all the relevant objects and their relationships?
- Satisfy all the user requirements?
- Satisfy all the requirements efficiently?
- Does the model
A model can be assumed to be correct if it satisfies the above questions. We will see later on as to how we satisfy these questions. Other key features of a data model are:
-
-
- Simplicity
- Maintainability
- Modifiability.
-
Simplicity is the hallmark of a quality data model. Simplicity relates to uncompounded, clarity, and direct expression. It refers to the ability of a model to express the real-world objects and relationships clearly and directly using simple constructs in the model. Simplicity can be achieved by having simple and easy to understand objects and
relationships as opposed to complex objects and relationships. The simpler the model the easier it is to maintain and extend the model in the future. By simple, we mean a model which has simple objects and relationships as opposed to complex objects and relationships. A complex object is an object which is used to represent many concepts together as a single unit. For example, if we create a single object called CUSTOMER_INVOICE to contain information about customer, order, shipping, invoice, and invoice items then CUSTOMER_INVOICE is a complex object. In this case we are trying to lump together different concepts like customer, order, and shipping information into one big object. It is extremely hard to manage complex objects. Objects should be simple. An object is simple if it represents one single concept. For example, an object called CUSTOMER representing the real-world customer is a simple object.
Maintainability refers to the ability to make changes in a model in a relatively constant environment. Modifiability refers to the ability to enhance a model to manage a changing environment. In most cases, the same design principles can be used to increase both maintainability as well as maintainability. In other cases, additional design guidelines may be needed to achieve an explicit goal of modifiability.
The first issue in building any kind of model is where to start? How do we go about identifying objects in the problem domain? These are incredibly challenging questions.
Identification of Objects and Attributes
There have been several attempts to propose methods to identify objects. Some of these are as follows.
- Extraction of nouns or noun-phrases from a verbal description of the problem
- Functional analysis
- Scenario analysis
- Transaction analysis
- Structured Analysis
- Report/Query Analysis.
Any of the above methods can be used to help us identify objects. However, none of these methods is sufficient by itself. We use a combination of several methods to identify objects. Obviously, the better understanding of a problem domain we have, the easier it is to identify objects of the problem domain. Let us, for a moment, think about how we first try to understand the business problem before we build a model for it. We try to understand the problem by collecting and analyzing information given by the users in the problem domain. During this process, users provide us with information in different forms. They provide information generally in the form of reports they want, queries they want, and business functions they want to be supported by the model.
Sometimes there is also a verbal description available for some of the functions to be supported by the model. These kinds of information are the starting point for identifying objects. If we know what kinds of reports and queries are needed by a user, we can look at the structure and the contents of these reports to determine what kind of basic objects we need to maintain so that we can generate those reports and queries. Here we can use the Report/Query Analysis to identify objects. The method of Report/Query Analysis looks at the structure and the content of reports and queries to identify objects. For
example, let us say that a user wants to have a system to print out a sales order with the following format shown in figure 4.
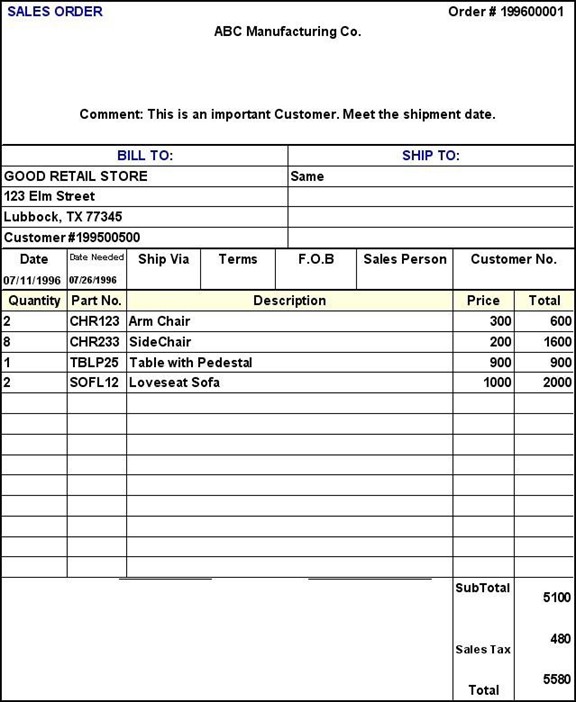
Figure 4. A Copy of Customer’s Sales Order
What data objects do we need to maintain to generate this report? We can identify the needed objects by looking at the structure and the content of the above sales order. A deeper look at the sales order reveals several points:
-
- The sales order contains information about several things–order, customer, salesperson, and order-items (i.e., products ordered under this order).
- Several order-items can be ordered under one order.
We can use a data structure scheme to show the sales order structure in a more formal way. This data structure scheme is shown below.
SALES_ORDER (order#, orderDate, customer#, billToName, billToStreet, billToCity, billToState, billToZip, shipToName, shipToStreet, shipToCity, shipToState, shipToZip, dateNeeded, orderComment, shipVia, terms, FOB,
salesPerson, (quantity, part#, description, price, total), subTotal, salesTax, orderTotal)
Here, we have replaced each field of the customer order with an attribute in the SALES_ORDER data structure scheme. The inner parentheses indicate that the enclosed group of attributes (the attributes in bold) can be repeated many times within a customer order. This group of attributes belongs to an order item. A data structure scheme of a report/query shows immediately, all the attributes needed to produce the corresponding report/query. In addition, it also captures the relationship among attributes corresponding to data fields present in the report/query. For example, every order includes one or more occurrences of an order item. One order item corresponds to one product. In other words, in every order, we have an order item for each product ordered by the customer. We also see that one order belongs to one customer. Obviously, a customer can place several orders with a company. We will discuss more about relationships later. For now, let us go back to the question of objects. What objects do we need to maintain information about in order to generate the sales order? Can we make the SALES_ORDER as an object? The answer is no. SALES_ORDER, as an object, contains information about too many different concepts such as customer, order, order-item, and product. This object would be an overly complex object to manage. We need to identify objects that are simple and basic, and each object represents one idea (thing). In this case, we see those things like customer, order, order-item, and product, considered separately, convey one idea and, therefore, each one of them is a better candidate for an object.
The steps of Report/Query Analysis can be summarized as below:
-
- For each report or query
- Study the structure and the content of the report or query.
- Represent the report structure as a data structure scheme replacing each field of the report with a corresponding attribute.
- Analyze the scheme for determining objects. Cluster attributes that seem to belong together.
- Name these clusters as objects.
- Look for hidden objects. For example, the object product is hidden inside the object order-item in the customer-order report. Some of the order-item attributes are derived from the product object.
- Collect all objects together. Collapse duplicate objects into one object by taking a union of all attributes of duplicate objects.
- Refine the objects and their attributes if necessary.
- For each report or query
The above steps help us identify objects needed for each report separately. Then we synthesize all objects together to determine a set of objects that are needed to generate all the given reports and queries. If there are still some user functions for which reports or queries are not known, then we can use the Function Analysis method to identify the additional objects.
In situations where we know the business activity to be supported, but do not know enough about the specific reports needed, Functional Analysis [ ] can be used to identify objects. The major steps of Functional Analysis are summarized below [ ]:
- Identify business activities and their sub-activities as clearly as possible.
- For each business activity:
- Identify all objects that are input to or consumed by the business activity.
- Example: Patient is input to the “Diagnose Patient” activity. Part is input to “Manufacture Product”.
- Identify all objects produced by the business activity.
- Example: Patient_diagnosis is the output of the “Diagnose Patient” activity.
- Identify all objects that are modified by the business activity.
- Example: The current status of the patient is modified by the “Diagnose Patient” activity.
- Identify all objects that are referred to but are not changed by the business activity.
- Example: Diagnosis codes (ICDM-9 codes) are referred to by the “Diagnose Patient” activity.
- Identify all objects that control or implement the business activity.
- Example: A Physician will perform the “Diagnose Patient” activity.
- Identify all objects that are input to or consumed by the business activity.
We will use some of these methods appropriately in our examples later.
Identification of Attributes of Objects
Attributes are used to capture and specify properties of objects. One needs to think about what properties of an object are relevant to a user. What traits qualify an object adequately? These traits can be thought of in terms of various categories. Some of these categories are:
- Identifying properties. These properties include identifier, name, address, or other descriptive traits of an object. Every object has an identifier that identifies it uniquely. The identifier is used to reference an object unambiguously. It also provides a convenient means for showing connections among objects.
- Status-defining properties. These properties include the status of an object. Examples are properties such as the status of an account, the current balance of a customer, credit-status of a customer, active vs. passive customer, event- enabled vs. event-disabled object, etc.
- Referencing properties. These properties are used to show connection with other objects. An example is a customer number as an attribute of the order object.
- Temporal properties. These are time-related properties. Examples are various kinds of dates, timestamps, etc.
The above categories of properties can be used as a guide to help identify properties of an object.
Identification of Relationships
Relationships among objects are user-defined. They are based upon the business rules that exist in the user’s problem domain. Relationships are imposed upon objects based upon the business rules which, in turn, depend upon user needs. There are very few inherent relationships among objects that are modeled in every situation. For example, consider a university registration system that maintains information about students. The university students might include a father and a daughter both registered and enrolled in classes.
Now, there is an inherent one-to-many relationship between a father and his children. But the university registration system does not need to capture and maintain this relationship.
There are several rule-of-thumb that help us identify the business rules and hence the relationships that must be captured in a model. These are as follows.
Rule-of-Thumb #1: Analysis of Report/Query Structure to Identify Implied Relationships
If a report-layout is known, it can be examined for possible relationships among the objects present in the report. Take the example of the sales order print-out shown in figure 4. The report structure implies that several order items associate with one customer order. It also shows that an order can belong to only one customer. There are several other relationships implied by the structure. These relationships are shown in figure 5.
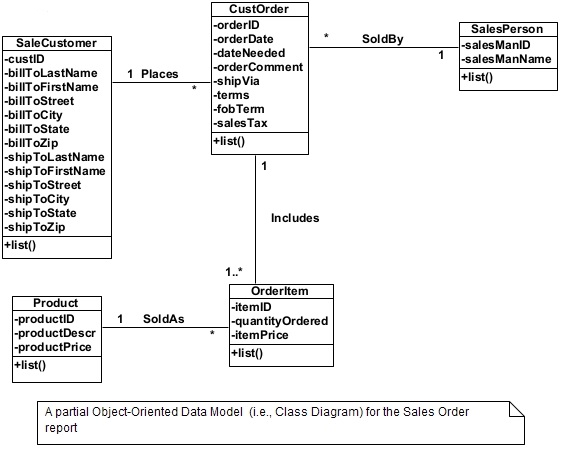
Figure 5. An incomplete Object-Oriented Data Model for the CUSTOMER ORDER report
Rule-of-Thumb #2: Analysis of Participation of Objects in a Business Activity
There may be an implied relationship among objects if these objects participate in a business activity. For example, let us take the business activity “Produce sales
agreement.” This activity creates a sales-agreement object. The activity uses several objects such as purchaser, seller, and product in creating this object. The sales-agreement object associates all these objects together. In fact the sales-agreement is basically a
“relationship object.” It captures relationships among other objects. Figure 6 shows these relationships. Some attributes, as an example, are included as part of the model in figure 6.
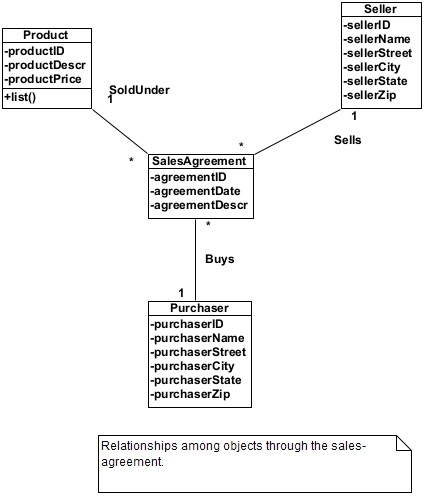
Figure 6. Relationships among objects through sales-agreement.
A relationship between two objects can be shown in diverse ways. In a pictorial representation, there is a physical connection between two or more objects implying a relationship. In a data structure scheme representation, a relationship is shown by including the identifier of one object as part of the other object.
Identification of Operations
Operations are actions performed on objects. Business activities use these operations to manipulate objects. For example, let us consider the business activity “Process a new customer order”. Several objects are affected by this activity. The customer object is either read or created if it does not exist already. The order object is created. Then the
Order-items are created. The product object is read to get the description and the price for the ordered items. Thus, we see that the business activity “Process a new customer order” needs to perform the following operations on objects:
- “Read customer” and/or “Create customer” operations on the customer object
- “Create order” operation on the order object
- “Create orderItem” operation on the orderItem object
- “Read Product” operation on the product object.
Other business activities may also require these and other operations on these objects. In addition to the standard operations, an object may have user-defined operations. For example, “List customer” is a user-defined operation on the customer object. “Compute orderTotal” is a user-defined operation on the order object. It is important to note that an operation defined on an object must work on that object or on the attributes of that object. We cannot define an operation and include it as part of an object if the operation does not manipulate that object. For example, it will be inappropriate to attach the operation
“Prepare product_sales_report” to the product object because “product_sales_report” is not the same thing as “product.” “Prepare product_sales_report” is an activity that uses several objects to prepare the sales-report. In fact, product-sales-report contains data that are derived from several basic objects. A basic object is an object that cannot be derived from other objects.
It is helpful to name operations using a “verb-noun” or a “verb-noun-phrase” notation. Here the verb denotes the action and the noun or the noun-phrase denotes the object or a part of the object. This notation helps us think about operations on an object more precisely.
Identification of operations on objects involves several steps. These are as follows:
- For each business activity, determine what objects participate in the activity.
- Determine what operations are performed on what objects by the activity.
- Collect all operations on an object and eliminate the duplicate operations.
Representation of the Structure of a data model
The structure of a data model shows the organization of objects in the model. It includes the objects and their inter-relationships. It is generally represented as a two-dimensional pictorial diagram. The structure of a data model can be represented at various levels of modeling. Some of these levels are:
-
- Conceptual level,
- Logical Level, and
- Physical level.
The terms “conceptual”, “logical”, and “physical” are frequently used in data modeling to differentiate levels of abstraction versus details included in the model.
A data model at conceptual level–a conceptual data model shows the data requirements of an organization at a high-level. It does not include any implementation details. But it does include detailed descriptions of real-world objects, relationships, and constraints. The two most widely used techniques to create and to document conceptual data models are Entity-Relationship (E-R) Diagramming and Object-Oriented Data Modeling.
At logical level, a logical data model is derived from the conceptual data model. A logical data model is based upon commercial database technology to be used for the eventual implementation of the database. Some of the database technologies are relational database technology, object-oriented database technology, and network database technology. Most logical data models are currently developed using relational database technology. The relational database management Systems (DBMS) like MySQL, MSFT SQL Server, and Oracle are based upon relational database technology.
At the physical data model level, we use the selected DBMS language to translate the logical data model into its physical representation within the DBMS. Here we specify the definition of tables, columns, indexes, and other constraints using the DBMS specific SQL.
We will elaborate on these different levels of models in subsequent posts. Here, we now discuss a secure data model.
Secure Data Model
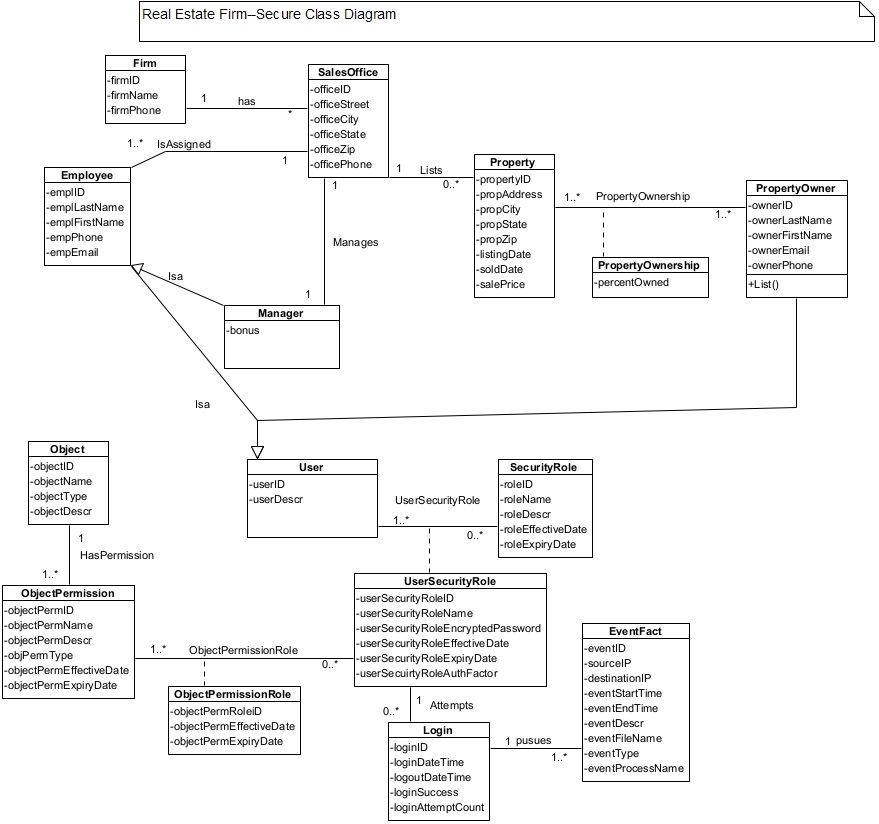
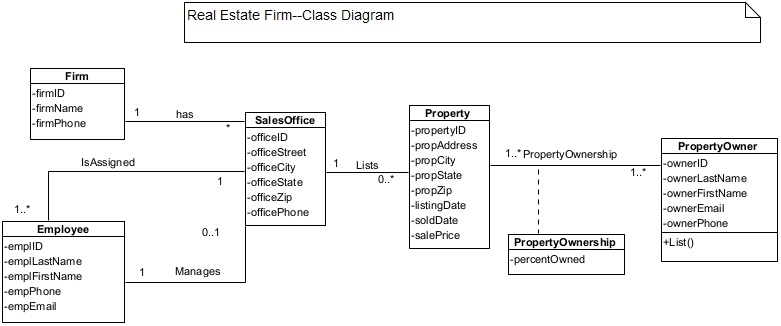
A secure data model is a data model that includes the additional data objects needed by the security functions (i.e., security use cases) as described in the article on secure function modeling. As discussed earlier, there are at least four security use cases—validate user input, use strong authentication, monitor brute force attack, and encrypt communication and data that should be integrated in every system. These security use cases need various kinds of security related data such as users’ login details, authentication, authorization details, and the data objects’ access permissions to deal with security threats. Here we use a Real Estate Firm case example to show a traditional data model and a secure data model.
Data Model—Real Estate Firm
Figure 7 shows a data model (i.e., a class diagram) with no data to deal with the security threats.
Secure Data Model–Real Data Model
Figure 8 shows a secure data model (i.e., a secure class diagram) that includes data to support the security use cases.